在当今大数据时代,Hadoop已成为构建强大、可扩展数据处理和存储系统的核心基础架构。它通过一套开源软件框架,为处理海量数据集提供了可靠的解决方案,尤其适用于商业智能、科学计算、日志分析等复杂场景。
一、Hadoop核心组件与基础架构
Hadoop的基础架构主要建立在两大核心组件之上:
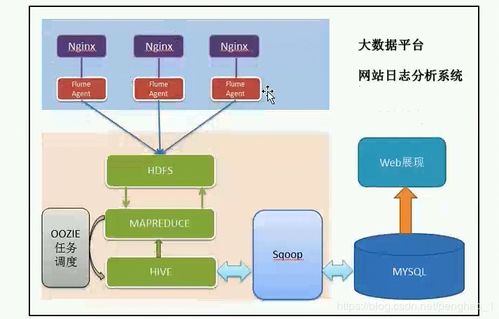
- Hadoop分布式文件系统(HDFS):作为存储层,它将大规模数据集分割成多个数据块,并分布存储在一个集群的多个计算节点上。其高容错性设计确保了即使单个节点失效,数据也不会丢失,同时支持流式数据访问,非常适合一次写入、多次读取的场景。
- MapReduce:这是Hadoop的计算引擎,采用“分而治之”的思想。它将计算任务分解为Map(映射)和Reduce(归约)两个阶段。Map阶段并行处理各个数据块,生成中间结果;Reduce阶段则汇总这些中间结果,生成最终输出。这种模型简化了分布式编程的复杂性。
围绕这两大核心,现代Hadoop生态系统还包括了YARN(资源调度与管理框架)、HBase(分布式数据库)、Hive(数据仓库工具)、Spark(内存计算引擎)等一系列服务与工具,共同构成了一个完整的数据处理平台。
二、构建“好程序”的设计原则
在Hadoop平台上开发高效、可靠的“好程序”,需要遵循以下关键原则:
- 数据本地化:尽可能将计算任务调度到存储数据的节点上执行,最大限度地减少网络传输开销,这是提升性能的关键。
- 容错与鲁棒性:程序设计应能优雅地处理节点故障。得益于HDFS的数据冗余和MapReduce的任务重试机制,开发者可以专注于业务逻辑,而无需过度担忧底层硬件故障。
- 水平扩展性:程序应能无缝利用新增的计算和存储节点。通过增加机器而非升级单机性能来提升处理能力,是Hadoop架构的根本优势。
- 批处理优化:针对Hadoop经典的批处理模式,程序应设计为适合处理大规模静态数据集,并充分利用I/O和CPU的并行能力。
三、全面的数据处理与存储支持服务
Hadoop不仅仅是一个计算框架,它提供了一整套支持服务,使得数据处理和存储变得高效、灵活且经济:
- 海量存储服务:HDFS能够以极低的成本(使用商用硬件)存储PB甚至EB级别的数据,为历史数据分析和数据湖建设提供了坚实基础。
- 多样化计算服务:除了批处理的MapReduce,通过YARN的资源管理,集群可以同时运行Spark进行实时/近实时分析、运行Tez优化Hive查询、运行Flink处理流数据等,满足不同延迟和吞吐量的需求。
- 数据管理与访问服务:Hive提供了类SQL的查询接口,降低了数据分析的门槛;HBase支持低延迟的随机读写;Sqoop和Flume简化了与关系数据库及日志系统的数据交换。
- 资源与作业调度服务:YARN作为集群的“操作系统”,负责统一管理计算资源(CPU、内存),并在多用户、多应用间进行公平、高效的调度,确保集群资源得到充分利用。
- 高可用与安全服务:通过NameNode高可用、数据加密、Kerberos认证及细粒度访问控制(如Apache Ranger)等机制,为企业级应用提供了必要的可靠性和安全保障。
结论
Hadoop基础架构通过其分布式存储与计算的核心设计,为构建处理海量数据的“好程序”提供了理想的土壤。其丰富的生态系统和全面的支持服务,使得它能够灵活应对从离线批处理到交互式查询等多种数据处理范式。尽管如今云原生和实时处理技术不断发展,Hadoop作为大数据领域的奠基者,其核心思想与架构依然在众多现代数据平台中发挥着不可替代的作用,是企业和组织实现数据驱动决策的强大后盾。